DataCanvas APS入门视频
产品定义
DataCanvas APS是面向数据科学团队的一站式数据分析平台,它是集数据准备、特征工程、算法实现、模型开发、模型发布、模型生产化管理于一体的机器学习平台,能够帮助企业快速构建数据分析应用。

产品优势
灵活、易用的企业级数据科学平台,加速从探索到生产落地的数据科学服务:
异构多引擎融合架构
灵活计算环境支持
APS平台功能基于Docker实现容器化封装,底层计算资源支持APS集群、Hadoop集群和GPU集群等多种模式,实现合理的计算资源利用。
数据抽象
通过序列化和反序列化完成模块之间数据交换,支持实现单机和分布式数据格式转换、不同语言之间数据转换、不同存储介质之间数据转换。
工作流混合编排
平台算子封装支持多语言模式,允许在同一个工作流中调用不同开发语言算子,同时支持工作流程嵌套,提升灵活性和复用性。
开放性算法支持
开箱即用“白盒”算法库
内置100多种算法模型,包括企业常用的统计分析、机器学习、深度学习算法,面向数据分析应用提供基础算法支持。
自定义算法
集成Web IDE环境,支持R、Python、Scala等常用数据分析语言,基于Docker技术实现算子的灵活封装、集成,并支持发布到已有算法库中。
开源机器学习/深度学习库集成
集成多种机器学习引擎(Tensorflow、Caffee、H2O等)并可开展协同工作。
支持大数据分析
全量数据处理
无缝集成Hadoop集群,利用Spark分布式内存计算提供强大的计算能力,实现全量数据分析。
实时数据处理
模型生产化,支持与实时流计算平台(RT)的无缝集成,实现模型结果数据在生产系统的实时消费。
工程化能力
模型生产全流程覆盖
平台提供的算子模块包括数据准备、特征工程、模型训练、模型评估、模型对比、模型发布,涵盖模型生产的标准流程,实现图形化、拖拽式工程建模。
Auto ML
通过配置目标实现自动化建模,支持自动算法选择、自动超参数优化、自动模型评估、自动模型选择。
模型生命周期管理
通过模型仓库模块实现对模型的版本管理,支持基于版本的模型生产上线、生产下线以及模型删除等操作。
DevOps支持
Docker微服务
平台提供的算子及生产的模型以运行在Docker容器内的微服务形式自动发布,实现与现有环境的融合以及功能复用。
持续交付
一站式完成模型开发、调试、测试以及生产上线的各流程,实现持续集成、持续交付。
自动更新
基于平台的工程化能力实现模型定期优化、自动更新。
团队协作
协作开发
支持团队不同角色(专家级数据科学家、数据分析师、编码人员、业务人员)成员之间协同开发,提升开发效率。
知识共享
支持模块共享,避免重复性工作。
产品特点
一站式数据科学平台服务,实现模型在企业生产系统快速落地:
一站式服务
集成可视化配置建模与IDE自定义编码环境,一站式完成数据科学应用从设计到生产的全部环节,适应数据应用快节奏的开发要求。
简化数据准备
支持多种数据连接器,轻松获取各类数据源的数据,包括本地数据、关系型数据库的数据、Hadoop大数据平台数据(HDFS、Hive等)。
降低大数据处理复杂性
APS支持分布式任务,可自动完成Hadoop、Spark的环境调用和任务分发执行,对使用者屏蔽了大数据技术组件的复杂性,使数据分析人员轻松获得大数据处理能力。
可扩展、可重用的模块库
基于Docker容器的自定义模块封装发布,一次编程,多处使用,可积累的模块库成为公司重要的智力资产,提升新模型的开发效率。
方便快速地创建模型
使用容器技术实现模块封装、调用,实现拖拽式建模工作流设计,提升建模效率。
易用的自动建模
通过界面配置基础数据和业务目标,实现一键式建模,自动完成算法建模、模型评估、模型选择,降低建模门槛。
自动模型生产发布
自动选择最优模型,实现自动模型发布功能,面向生产系统提供标准REST API调用服务。
多方位安全保障
企业私有环境部署,确保环境安全;面向用户、角色、工作空间的多层级访问控制,保障数据安全;用户的访问、编辑、操作等任何行为都可追溯,实现责任认定。
多维度可靠性支撑
平台服务采用负载均衡和高可用设计;完善的容灾备份机制,提供数据的备份与恢复方案,以及针对异常情况的自动化处理。
自动化运维
自动部署,支持根据需求动态调整集群规模;自动化调度,支持定时或周期性的执行方式;全局监控,及时了解调度执行情况。
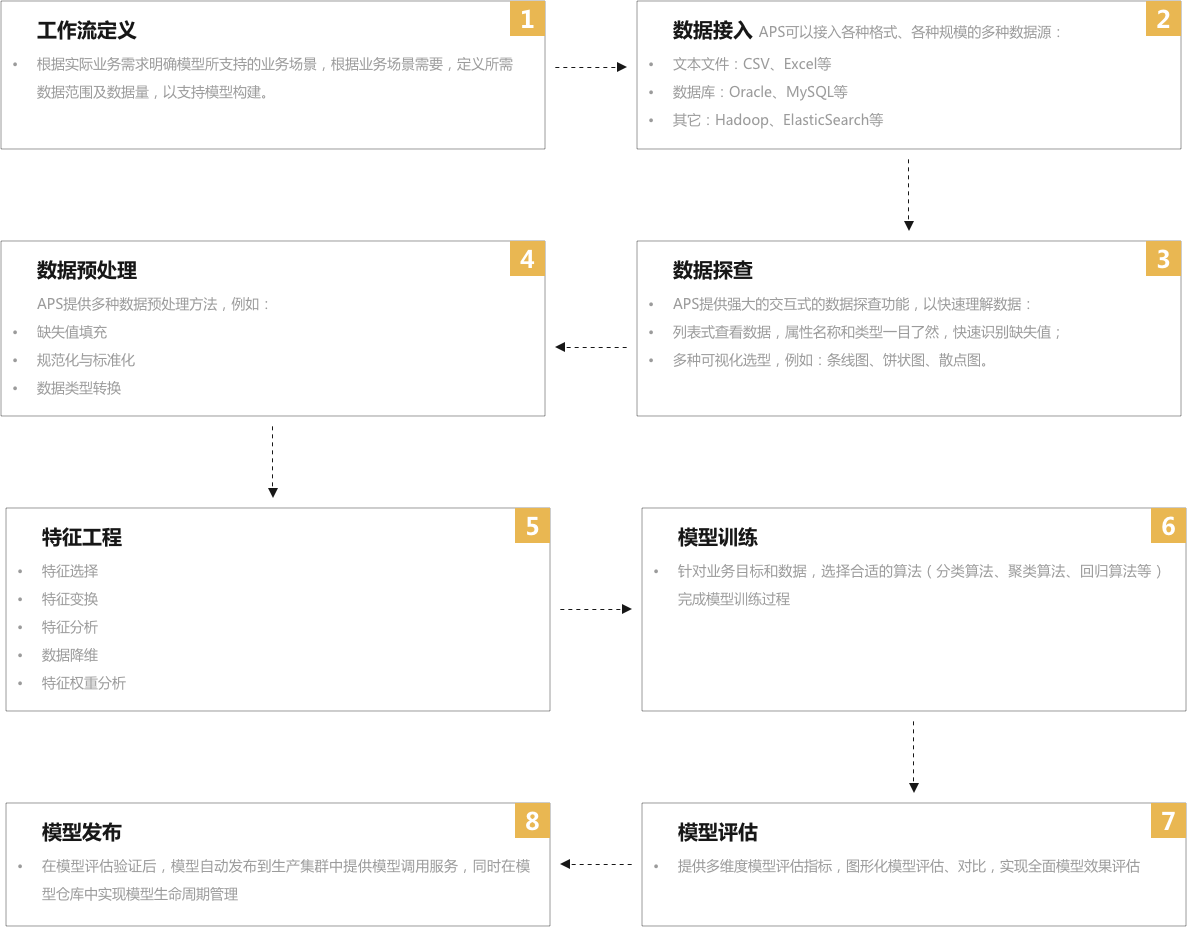
APS典型工作流设计流程
APS数据科学平台支持拖拽式、配置式数据挖掘工作流设计,使数据科学家能更加高效的完成从模型训练到模型生产应用的工作任务。一般而言,实现一个完整的工作流,包括如下几个重要步骤:
APS在金融领域的典型应用场景
银行存款结构分析
随着利率市场化的持续推进、存款保险制度的正式实施和互联网金融的不断冲击,银行业负债业务正面临越来越多的挑战,受多重因素影响,商业银行依靠传统存贷款利差赚取利润的空间逐步收窄。挖掘与分析银行海量业务数据,清晰展现零售存款结构现状,精准衡量零售客户贡献度,有效识别网点业务发展情况,协助银行创新经营思路,丰富产品类型,灵活运用多种负债工具,建立网点大数据绩效评价机制,利用数据结论支撑存款产品定位、零售客户精准营销及网点优化调整,将有助于银行打造新常态下零售业务发展的新动力。
银行网点服务数据分析
营业网点是银行面向金融消费者提供服务的主要窗口,在经济转型、利率市场化、经济社会互联网化程度不断加深、金融消费行为快速变化的新形势下,传统银行提升网点效率,推动网点转型势在必行。探索分析网点效能,利用大数据分析手段更加清晰、准确的识别网点现状,将有助于银行更有针对性的开展转型升级。
银行套取手续费智能监测
各行目前均存在可疑客户利用银行卡疑似套取手续费,协助其他机构套取银行中间业务收入的行为,严重损害了银行利益。基于大数据分析的“套取手续费风险监测”模型可以及时发现银行卡用卡风险,在套取手续费行为发生后,能够第一时间有效筛查可疑客户和可疑交易,发现套取手续费交易或疑似行为,以便帮助银行及时进行资金冻结等风险防范措施。
银行ATM加钞策略模型优化
离行式或在行式ATM可以显著降低营业网点的人工成本,但加钞取款受到节假日、天气、取款客户分群等多种因素影响,传统的加钞主要依赖于人工估算,这种方式不但带来巨大的工作量,而且降低了银行收益。基于大数据分析的加钞策略模型,可以较准确的预测每天客户的存取款金额,从而确定加钞频次和加钞金额,达到优化ATM机具资金运营优化的目的。
银行理财产品精准推荐
当前银行业传统金融服务面临互联网金融的巨大挑战,急需通过金融产品创新、服务质量提升等手段,提升自身竞争力和客户满意度。银行积累了大量高价值的运营数据,基于大数据分析的手段,可以帮助银行从从客户个人财务状况信息中分析客户特征,从而可以定向推荐合适的理财产品,以小代价获取大收益。
银行客户关系管理
如何在拓展新客户的同时预防老客户流失是银行进行客户关系管理的重要方面。银行具有大量客户的交易数据,利用数据挖掘技术,可以对处于不同生命周期的客户提供具有针对性的服务和产品,从而提高客户忠诚度,也可以在一定程度上及时转移关联因子,找到客户中比较类似的转移者,及时发现客户异常行为,以便银行降低客户流失。
 如果您对此感兴趣,欢迎问问展商吧!
暂无数据暂无数据如果您对此感兴趣,欢迎问问展商吧!
如果您对此感兴趣,欢迎问问展商吧!
暂无数据暂无数据如果您对此感兴趣,欢迎问问展商吧!



 CHN
CHN EN
EN